
DeepSeek上线专家模式:国产AI激战正酣,V4能否复刻去年春节炸场?
来源:澎湃新闻
2026-04-08 13:29:01
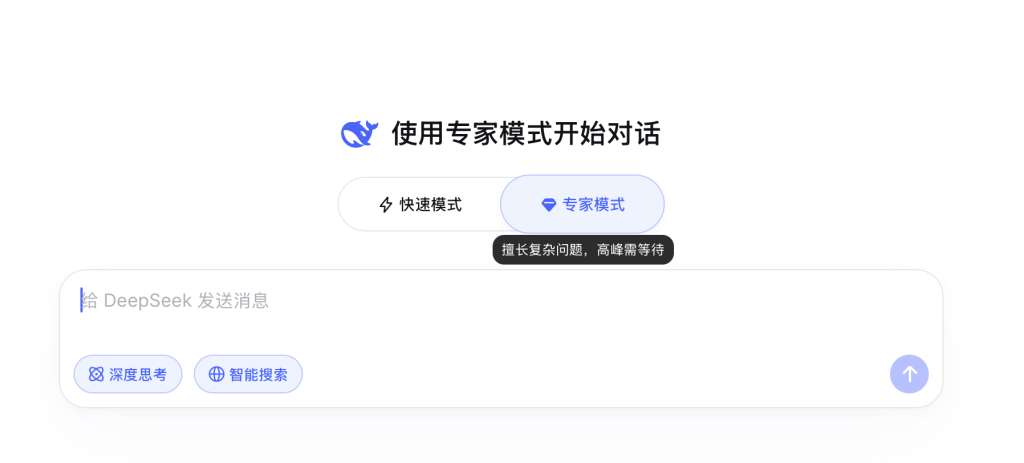
4月8日,澎湃新闻记者查询发现,在最新版本中,DeepSeek输入框上方新增“快速模式”与“专家模式”,网页显示,快速模式适合日常对话,即时响应,支持图片和文件中的文字识别;专家模式擅长复杂问题,这也是DeepSeek在官网页面首次引入分层模式。
这也让DeepSeek更新V4的悬念再度成为大家讨论的热点,综合外媒报道和社交媒体、多方渠道信息,DeepSeek大概率在今年4月正式上线V4版本。
此前不少消息也透露出端倪:3月29日至31日,DeepSeek官方网站连续三天出现不同程度异常,涉及网页对话、App及API等,故障分别持续约1小时48分、10小时13分和1小时3分。其中,3月29日晚上22点开始,一直到30日早上7点,服务出现长达8小时的大规模访问异常,大量用户遭遇页面卡顿、反复提示“服务器繁忙”甚至功能完全中断。
外界猜测,DeepSeek出现大规模宕机的核心原因,是V4更新所导致,对此,DeepSeek内部人士没有回应消息的真实性,而是向澎湃新闻记者表示:非常期待。
今年1月12日,DeepSeek曾发布一篇新论文《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》(基于可扩展查找的条件记忆:大语言模型稀疏性的新维度),梁文锋位列作者名单中,这篇论文为北京大学和DeepSeek共同完成。据分析,这篇论文的核心直指当前大语言模型存在的记忆力“短板”,提出了“条件记忆”这一概念。
2月13日,澎湃新闻记者曾独家获悉,DeepSeek网页/ APP正在测试新的长文本模型结构,支持1M上下文。其API服务不变,仍为V3.2,仅支持128K上下文。大家当时也猜测,DeepSeek或将在今年春节再次“炸场”发布新模型,复刻去年春节现象级轰动。
不过,春节AI大战虽然热闹,但DeepSeek却始终静悄悄,也让相关期待一度落空。
据券商研报显示,DeepSeek最新的V4模型亮点将聚焦国产化。野村证券分析,作为去年推出DS-V3/R1并搅动全球AI产业链的玩家,DeepSeek的全新技术布局不仅将推动中国AI产业链创新周期加速,更将通过技术创新,在算法与工程层面缩小中国与全球大模型产业的差距。
业内人士普遍认为,此次V4发布,对于DeepSeek来说难度颇大,要复刻去年春节期间炸场的轰动性颇有技术挑战,因为国产大模型已经卷入深水战场,竞争极度激烈。
4月8日,智谱正式发布GLM-5.1,记者发现,在年内涨价超八成后,智谱GLM再度提价10%。调价后,GLM-5.1在Coding场景的缓存命中Token价格已接近Anthropic旗下Claude Sonnet4.6水平。
据悉,这是国产大模型首次在核心场景实现与海外头部厂商的价格对齐。一年前,国产大模型厂商还在以降价90%以上争夺市场份额。这一转折表明国产大模型不再单纯依靠大幅降价争夺市场,而是以性能溢价锚定国际基准。
数据显示,GLM-5.1在编程能力上继续保持领先,在SWE-bench Pro、Terminal-Bench、NL2Repo三大代码评测基准的综合平均分中,取得全球第三、国产第一、开源第一;此外,有别于当前以分钟级交互为主的模型,GLM-5.1能够在单次任务中持续、自主地工作长达8小时。
3月18日,MiniMax(上海稀宇极智科技有限公司)发布新一代Agent旗舰大模型M2.7,首次展示“模型自我进化”路径。该模型通过构建Agent Harness体系,深度参与自身训练与优化流程,在部分研发场景中可承担30%—50%的工作量,并在内部评测集上实现约30%的效果提升。
据介绍,在核心能力上,M2.7在SWE-bench Pro中取得56.22%的成绩,接近国际一线水平;同时在VIBE-Pro、Terminal Bench2等真实工程测试中表现突出,支持端到端项目交付与复杂系统理解。办公场景方面,其在GDPval-AA的ELO得分是1495,为开源模型中最高,并显著提升Office文档处理与多轮编辑能力。
截至8日港股午盘,智谱(02513.HK)涨14.06%,报888.5港元,市值3961亿港元。MiniMax(0100.HK)涨6.9%,报1015港元,市值3183亿港元。
责任编辑:张誉耀